
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- Algorithm
- 운영체제
- 알고리즘
- Galera Cluster
- MSA
- JavaScript
- 자료구조
- MySQL
- 파이썬
- Java
- Heap
- mongoDB
- Kafka
- 백준
- 디자인 패턴
- 컴퓨터구조
- design pattern
- Spring
- react
- C
- IT
- Proxy
- spring webflux
- JPA
- OS
- Data Structure
- c언어
- 네트워크
- 자바
- redis
- Today
- Total
시냅스
검색기능 개발 (MySQL Full-Text Index, Search) 본문
이 글에서는 Full-Text Index + Search 에 대한 설명과 프로젝트에서 사용하게된 이유,
Full-Text Search 를 JPA 에서 사용하는 방법을 설명합니다.
현재 진행하고 있는 프로젝트는 공연에 대한 예매시스템을 구축하고 있습니다.
사용자들은 공연에 대한 정보를 확인하거나 예매할 때 검색을 사용하기에 기능을 구현할 필요가 있었습니다.
여기에 고민한 것은 Elasticsearch 와 MySQL 의 Full-Text Search 였습니다.

Elasticsearch 는 검색에 대한 분명한 장점이 있습니다.
자체적으로 분산 아키텍처를 구축하고 데이터를 샤딩하여 저장하고
역 인덱스를 통한 빠른 데이터 참조를 가능하게 합니다.
다만 구축하려는 검색기능은 높은 가용성이나 정확성을 요구하지 않고
Elasticsearch 는 구축하는 비용이 높고 이에 따른 유지보수가 필요합니다.
따라서 MySQL의 Full-Text Search 를 고려하였습니다.
Full-Text Search
Full-Text Search 는 텍스트 필드의 모든 단어를 인덱싱하여 유연한 검색을 가능하게 합니다.
특정 문구를 포함하거나, 특정 단어와 가장 근접한 레코드를 찾거나, 단어 또는 문구의 유사성을 통한 레코드 정렬을 가능하게 합니다.
이러한 유사한 기능으로는 익히 알고 있는 'Like' 가 있습니다.
다만 Like 를 쓰지 않고 Full text Search 를 쓰는 이유는 다음과 같습니다.
Like 를 쓰지 않은 이유
- Like 또한 특정 패턴이 있는지에 대한 검색을 수행한다.
- 만약 컬럼에 인덱스가 걸려있고 'ABC%' 와 같은 값이라면 인덱스를 사용한다.
- B+Tree 는 정렬되어 있을 것이기 때문에
- 다만 '%ABC' 라고 한다면 ABC 로 끝나는지에 대한 Table Full Scan 이 이뤄진다.
- 이 때 모든 레코드가 매치되는지 확인한다.
- '%ABC%' 도 마찬가지이다.
- 따라서 대량의 데이터에서 검색을 수행할 경우 성능이 현저히 저하된다.
위와 같은 이유로 Full-Text Search 를 사용하는 것이 적합해보입니다.
Partition?
여기에서 고려할 것은 한가지 더 있습니다.
만약 Full-Text Index 를 테이블에 설정한다면 Partition 을 걸지 못하게 됩니다.
Partition 을 걸지 못한다는 것은 테이블 볼륨이 아주 커졌을 때를 대비하지 못하게 된다는 뜻과 같습니다.
볼륨이 커지면 물리적으로 나누고 논리적으로는 그룹을 맺게 하는 수평적 파티션을 통해 가용성을 높이는데
Full-Text Index 를 사용함으로써 이를 구현할 수 없게 되기 때문입니다.
따라서 현재 검색하려고 하는 공연의 데이터가 약 10년 정도 서비스할 때 몇 건이 생길지에 대한 추산이 필요합니다.
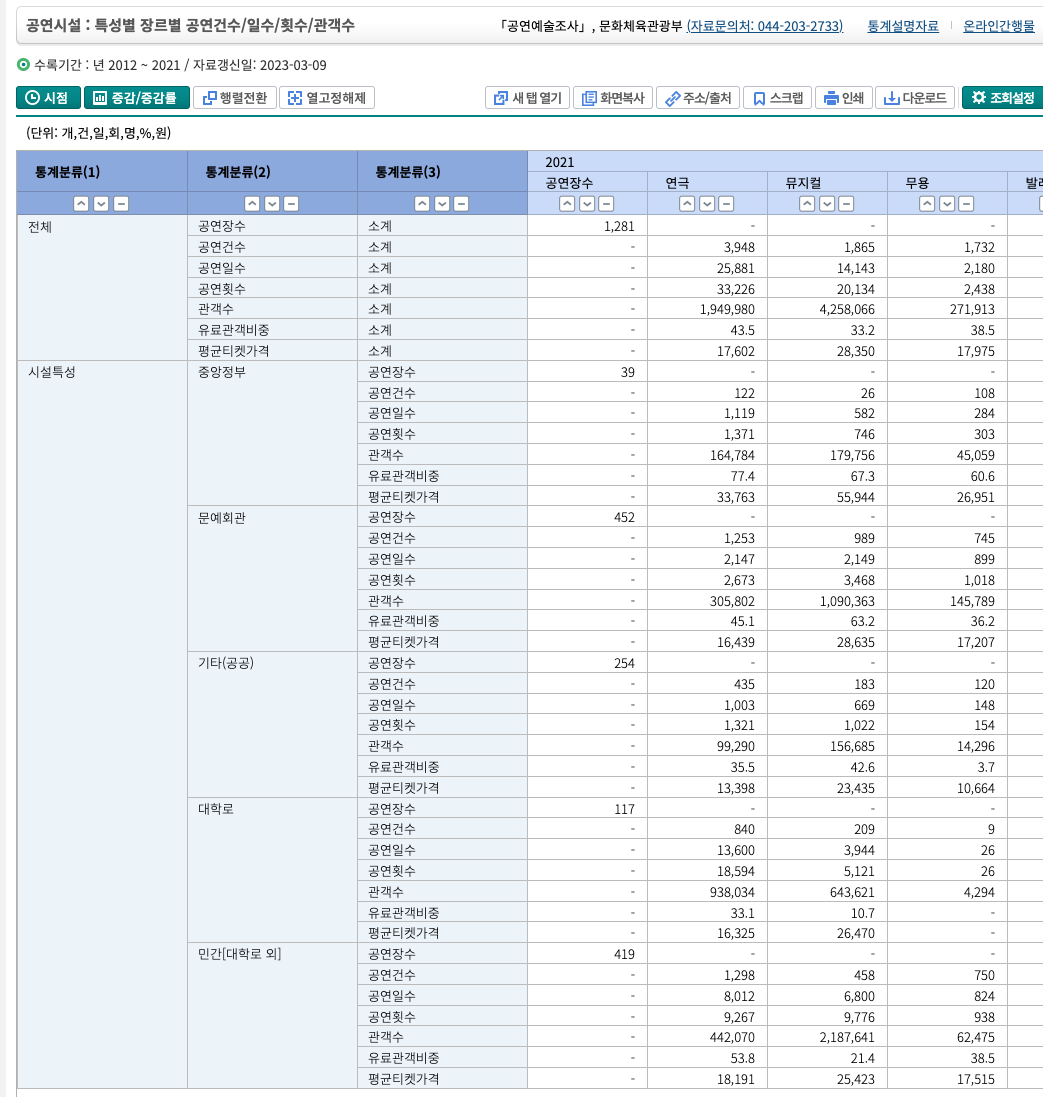
통계청 자료를 바탕으로 조사해본 바 2012 - 2021 년도 까지 약 346,076 건의 공연이 있었습니다.
코로나의 여파로 주춤했던 2020, 2021을 1.5 배수 한다고 하더라고 378,391 건으로
충분히 파티션을 설정하지 않고도 소화가 가능해보였습니다.
따라서 Full-Text Search 를 사용하기로 결정하였습니다.
본격적인 구현에 앞서 Full-Text Search 의 구성에 대해 알아보겠습니다.
Parser
검색 및 분석을 담당하는 컴포넌트 입니다.
텍스트에서 각 단어를 추출하고 Full-Text Index 에 저장하여 검색할 때 사용됩니다.
- stop-word
- 불용어 처리
- 가치 없는 단어 모두 필터링
- MySQL 에서 상수로 처리
- 형태소 분석
- 한국어의 경우 학습되지 않았다면 무조건 공백으로 토큰을 나눔
- 따라서 단어가 정확히 일치해야만 검색 결과를 확인할 수 있다.
- 불용어 처리
- n-gram
- 위의 불용어를 처리하기 어렵기 때문에(언어 샘플, 학습 등) 도입됨
- 단순히 키워드를 검색하기 위한 인덱싱
- 본문을 무조건 몇 글자씩 잘라서 인덱싱
위의 차이와 같이 stop-word 는 한국어의 경우 공백을 토큰으로 나눠 검색하기 때문에
부정확한 토큰을 검색으로 수행하면 결과값이 아예 나오지 않을 수 있습니다.
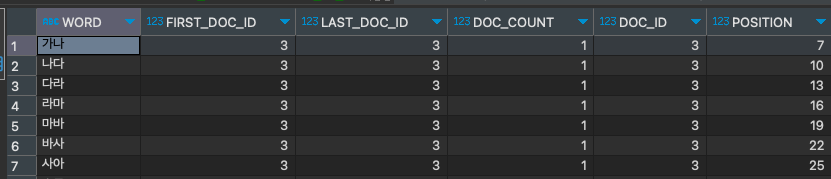
다만 n-gram 은 만약 레코드가 '가나다라마바사아' 라는 데이터를 인덱싱했다면
가나/나다/다라/라마/마바/바사/사아 로 인덱싱이 저장되기 때문에 비교적 검색이 수월해집니다.
실제로 n-gram parser 가 인덱싱한 데이터를 확인해보겠습니다.
set global innodb_ft_aux_table = 'db/table';
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE;위와 같은 쿼리를 통해 Full-Text Index 데이터를 확인할 수 있고
아래는 '가나다라마바사아' 라는 데이터를 적재 후 실행한 결과입니다.
검색방식
- natural language search
- 단어 단위로 분리한 후 해당 단어가 하나라도 포함되는 레코드가 있다면 반환
- 다만 지정된 길이보다 짧은 토큰일 경우 무시된다.
- show variables like '%ft_min%'; 쿼리를 통해 최소 토큰 길이를 확인할 수 있읍
- boolean search
- 특정한 규칙을 가지고 단어가 포함되는 레코드를 찾음
- '+title -content' 라면 title 이 포함되는 것은 찾되 content 가 포함된 레코드는 제외함
- 만약 단순히 '개발자' 라고 검색한다면, '+개발 +발자' 와 같은 꼴로 검색됨
- 자세한 옵션은 아래의 링크에서 확인 가능하다
- MySQL Boolean Search Operator Manual
현재 프로젝트는 아주 간단한 검색만을 요구하므로, boolean mode 에서 지원하는 다양한 옵션은
n-gram parser 의 인덱싱으로 대체 가능합니다.
select * from test_tb tt
where match (first_name) AGAINST('Joss elyn' in boolean mode);
-- // 200 rows fetched 1.18s
select * from test_tb tt
where match (first_name) AGAINST('Joss elyn' in natural language mode);
-- // 200 rows fetched 200ms
또한 성능에서의 차이점도 존재합니다.
위에서 설명했듯 '개발자' 라는 토큰에 대해 + 옵션을 적용하므로 교집합에 대한 추가적인 연산이 필요합니다.
테스트 데이터 1,000만건이 들어있는 테이블을 기준으로 동일한 parser 의 적용과,
다른 search mode 를 적용했을 때 약 6배의 성능적 차이를 보입니다.
이는 아주 간단한 검색에서의 구현으로, 검색식이 복잡해진다면 차이는 더욱 극명할 것으로 생각됩니다.
따라서 n-gram parser 와 natural language search 를 함께 사용하기로 하였습니다.
아래에서는 index 설정과 JPA repository 구현을 살펴보겠습니다.
Full-Text Search 구현
참고로, JPA 에서는 아직 Full-Text 에 대해 지원하지 않습니다.
(h2 에서도 마찬가지 입니다. 참고 링크)
따라서 직접 쿼리로 index를 적용해주시거나, SQL 파일을 실행하시는 것을 권장합니다.
-- table 생성시 index 설정
create table shows (
-- // columns
fulltext (title, artist, place) with parser ngram
);
-- table 생성 후 index 설정
ALTER TABLE test_tb ADD FULLTEXT(first_name) with parser ngram;MySQL 에서는 default 가 stop-word 이므로 parser ngram 을 사용한다는 옵션이 필요합니다.
현재는 title, artist, place 로 Full-Text index 가 3개가 걸려있으니 검색은 다음과 같이 실행합니다.
SELECT *
FROM shows
WHERE MATCH (title, artist, place)
AGAINST('테스트' in NATURAL LANGUAGE mode);위와 같은 쿼리를 통해 검색을 수행합니다.
'테스트' 와 매치되는 인덱스를 확인하여 결과를 반환할 것입니다.
아래는 JPA 에서 쿼리를 실행하는 방법입니다.
@Query(value = "SELECT *" +
" FROM shows" +
" WHERE MATCH(title, artist, place)" +
" AGAINST(?1 IN NATURAL LANGUAGE MODE)" +
" ORDER BY ID DESC",
nativeQuery = true)
Page<Show> findAllByFullTextSearch(Pageable pageable, String keyword);말씀드렸듯, JPA 에서는 아직 Full-Text Search 에 대한 지원이 없어 JPQL 대신 nativeQuery 로 실행해야 합니다.
이외에는 일반 쿼리를 수행하는 것과 동일합니다.
이 글에서는 MySQL Full-Text Search의 설명과 사용하는 이유, 구현 방법에 대해 설명했습니다.
필요하신 만큼 취사-선택하시어 도움이 되시길 바랍니다.
끝!
참고:
https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html
MySQL :: MySQL 8.0 Reference Manual :: 12.9 Full-Text Search Functions
12.9 Full-Text Search Functions MATCH (col1,col2,...) AGAINST (expr [search_modifier]) search_modifier: { IN NATURAL LANGUAGE MODE | IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION | IN BOOLEAN MODE | WITH QUERY EXPANSION } MySQL has support for full-text i
dev.mysql.com
https://stackoverflow.com/questions/41892179/elastic-search-full-text-vs-mysql-full-text
Elastic search full text vs mysql full text?
I am trying to implement search functionality in my laravel app. Angolia is not preferred by my supervisors due to data security problems. Other than that one good option is to implement elastic se...
stackoverflow.com
https://esbook.kimjmin.net/06-text-analysis/6.1-indexing-data
6.1 역 인덱스 - Inverted Index - Elastic 가이드북
전통적인 RDBMS 에서는 위와 같이 like 검색을 사용하기 때문에 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸리고, row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가
esbook.kimjmin.net
'데이터베이스 > MySQL' 카테고리의 다른 글
| Galera Cluster 의 Boostrap 과 구성 파일 이해 (0) | 2023.10.24 |
|---|---|
| GTID 와 Galera Cluster (1) | 2023.10.09 |
| 페이징 성능 최적화 - No Offset 은 왜 빠를까? (0) | 2023.06.10 |
| MySQL 커버링 인덱스 Covering Index (2) | 2023.05.29 |
| MySQL 단편화 Fragmentation 의 이해와 해결 (2) | 2023.05.13 |



