
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- MSA
- Road to Web3
- Java
- redis
- spring webflux
- Ethereum
- 백준
- 자바
- 운영체제
- Algorithm
- Blockchain
- Galera Cluster
- MySQL
- mongoDB
- 네트워크
- 디자인 패턴
- react
- OS
- JPA
- JavaScript
- Data Structure
- design pattern
- 컴퓨터구조
- Spring
- IT
- 파이썬
- Heap
- C
- 알고리즘
- 자료구조
Archives
- Today
- Total
시냅스
다중 처리기 스케줄링 Multiple-Processor Scheduling 본문
다중 처리기 스케줄링 Muliple-Processor Scheduling
- 여러 스레드가 병렬로 실행되어 부하 공유(load sharing)이 가능하다.
- 그러나, 스케줄링 문제는 그에 상응하여 더욱 복잡해진다.
다중 처리기 스케줄링에 대한 접근 방법 Approach to Multiple-Processor Scheduling
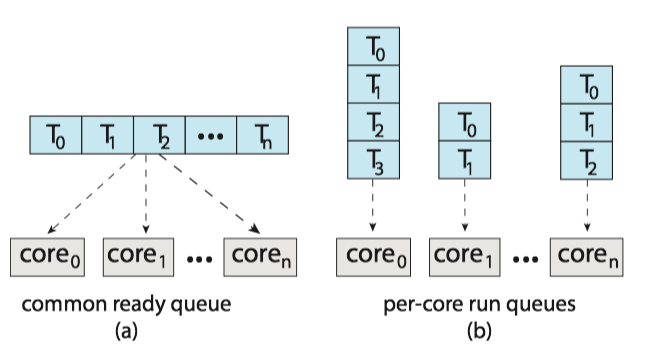
- 비대칭 다중 처리 : 하나의 처리기가 마스터 서버로 모든 스케줄링 결정과 I/O 처리, 다른 시스템의 활동을 취급하게 하는 것
- 단점은 마스터 서버가 전체 시스템 성능을 저하할 수 있는 병목이 된다는 점이다.
- 대칭 다중 처리 (SMP) : 표준 방법으로, 각 프로세스가 스스로 스케줄링을 할 수 있다.
- 모든 스레드가 공통 준비 큐에 있을 수 있다.
- 경쟁 조건으로부터 공통 Ready Queue를 보호하기 위해 락킹 기법의 하나를 사용할 수 있다.
- 락킹은 매우 경쟁이 심할 것이고, 공통 Ready Queue는 병목을 겪을 수 있다.
- 각 프로세서는 자신만의 스레드 큐를 가질 수 있다.
- 캐시 메모리를 효율적으로 사용할 수 있다.
- 큐마다 부하의 양이 다를 수 있다.
- 균형 알고리즘을 사용하여 모든 프로세서 간 부하를 균등하게 만들 수 있다.
- 모든 스레드가 공통 준비 큐에 있을 수 있다.
다중 코어 프로세서 Multicore Processors
- 동일한 물리적인 칩 안에 여러 개의 처리 코어
- 각 코어는 운영체제 입장에서 개별적인 논리적 CPU처럼 보이게 된다.
- 단일 코어보다 속도가 빠르고 적은 전력을 소모한다.
- 메모리 스톨 (memory stall) : 프로세서가 메모리에 접근할 때 데이터가 가용해지기를 기다리면서 시간을 허비하는 상황 -> 프로세서가 메모리보다 훨씬 빠른 속도로 작동하기 때문에 주로 발생하거나 캐시 미스(캐시 메모리에 없는 데이터를 액세스)로 인해 발생할 수 있다.
- 해결하기 위해 하나의 코어에 2개 이상의 하드웨어 스레드를 할당한다.
- 메모리를 기다리는 동안 하나의 하드웨어 스레드가 중단되면 코어가 다른 스레드로 전환할 수 있다.
- -> 칩 다중 스레딩 (Chip Multi-threading, CMT)라고 부른다.
- 거친(coarse-grained) 다중 스레딩 vs 세밀한(fine-grained) 다중 스레딩
- 거친 다중 스레딩
- 스레드가 메모리 스톨과 같은 긴 지연시간을 가진 이벤트가 발생할 때까지 한 코어에서 수행된다.
- 긴 지연시간을 갖니 이벤트에 의한 지연 때문에 코어는 다른 스레드를 실행하게 된다.
- 그러나 그 프로세서 코어에서 다른 스레드가 수행되기 전에 명령어 파이프라인이 완전히 정리되어야 하므로 스레드간 교환 비용이 크다.
- 세밀한 다중 스레딩
- 명령어 주기의 경계에서 같이 좀 더 세밀한 정밀도를 가진 시점에서 스레드 교환이 일어난다.
- 그러나 세밀한 시스템의 구조적 설계는 스레드 교환을 위한 회로를 포함한다.
- 그 결과 스레드 간 교환의 비용이 적어진다.
- 거친 다중 스레딩
부하 균등화 Load Balancing
- 부하를 모든 처리기에 균등하게 배분
- push 이주와 pull 이주
- push 이주
- 특정 태스크가 주기적으로 각처리기의 부하를 검사한다.
- 만일 불균형 상태로 발곃지면 과부하인 처리기에서 쉬고 있거나 덜 바쁜 처리기로 스레드를 이동 (push) 시킴으로써 부하를 배분한다.
- pull 이주
- 쉬고 있는 처리기가 바쁜 처리기를 기다리고 있는 프로세스를 pull
- push 이주
- push 와 pull은 서로 배타적이지 않고 병렬적으로 구현 가능하다.
처리기 선호도 Processor Affinity
- 프로세서 선호도 : 스레드를 한 프로세서에서 다른 프로세서로 이주시키지 않고 같은 프로세서에서 계속 실행시키면서 warm cache를 이용
- 스레드가 다른 처리기로 이주하면 프로세서의 첫번째 캐시 메모리는 무효화, 두번째 프로세서의 캐시는 다시 채워져야 한다.
- 이에 따른 비용이 많이 들기 때문에 프로세서 선호도를 사용한다.
- 프로세서마다 자신만의 큐(SMP)를 사용하면 스레드는 항상 동일한 프로세서에 스케줄 되므로 warm cache의 내용을 확인할 수 있다.
- 약한 선호도 (soft affinity) : 프로세스를 실행시키려고 노력하는 정책을 가지고 있지만 보장하지 않을 때
- 프로세스를 특정 처리기에서 실행시키려고 노력은 하지만 프로세스가 처리기 사이에서 이주하는 것이 가능하다.
- 강한 선호도 (hard affinity) : 시스템 콜을 통하여 프로세스는 자신이 실행될 처리기 집합을 명시할 수 있다.
이기종 다중 처리 Heterogeneous Multiprocessing
- 전력 소비를 유휴 수준으로 저장하는 기능을 포함하여 클록 속도 및 전력 관리 측면에서 차이가 나는 코어를 사용하여 설계한 것.
- 특정 요구에 따라 특정 코어에 작업을 할당하여 전력 소비를 잘 관리하는 것이 목적이다.
- 코어 간 속도 차이가 있다.
'운영체제' 카테고리의 다른 글
| 프로세스 동기화 Process Synchronization (0) | 2022.04.28 |
|---|---|
| 실시간 CPU 스케줄링 Real-Time CPU Scheduling (0) | 2022.04.21 |
| 스레드 스케줄링 Thread Scheduling (0) | 2022.04.21 |
| 스케줄링 알고리즘 Scheduling algorithm (0) | 2022.04.21 |
| CPU 스케줄링 CPU Scheduling (0) | 2022.04.21 |
'운영체제' Related Articles
more



Comments