
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 백준
- Algorithm
- redis
- 디자인 패턴
- 자료구조
- Java
- Galera Cluster
- 네트워크
- 운영체제
- spring webflux
- MySQL
- mongoDB
- Heap
- Spring
- OS
- C
- c언어
- Data Structure
- react
- IT
- 자바
- 알고리즘
- Kafka
- JavaScript
- JPA
- design pattern
- 파이썬
- Proxy
- 컴퓨터구조
- MSA
- Today
- Total
시냅스
가상 메모리, Virtual Memory 본문
Chapter 10 Virtual Memory
물리 메모리와 논리 메모리를 완전히 분리하여 프로세스 전체가 메모리 내에 올라오지 않더라도 실행이 가능하도록 하는 기법이다.
- 가상 메모리를 정의하고 그 이점을 설명한다.
- 요구 페이징을 사용하여 페이지가 메모리에 적재되는 방법을 설명한다.
- 페이지 교체 알고리즘에 대해 알아본다.
- 프로세스의 작업 집합과 프로그램 지역성에 대해 알아본다.
10.1 배경 Background
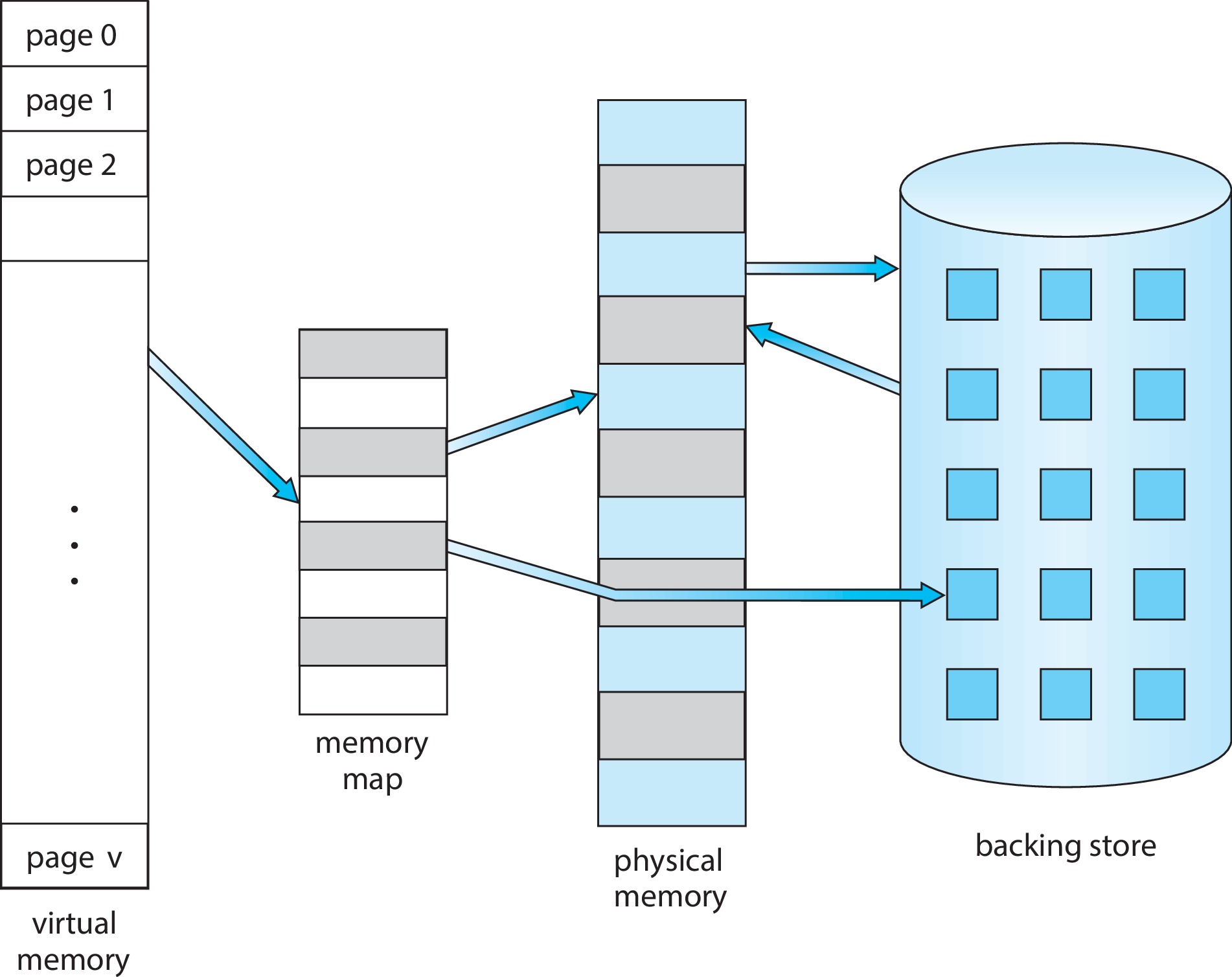
프로세스 전체가 메모리에 올라와 있다면 항상 메모리에 올라와 있지 않아도 되는
- 오류 처리 코드,
- 필요 이상으로 많은 공간을 점유하는 자료구조,
- 옵션이나 자주 사용되지 않는 기능 등
또한 상주하게 된다.
만일 프로그램을 일부분만 메모리에 올려놓고 실행할 수 있다면,
- 프로그램은 물리 메모리 크기에 제약받지 않게 된다.
- 각 프로그램이 작은 메모리를 차지하므로 더 많은 프로그램을 동시에 수행할 수 있게 된다.
- 프로그램을 메모리에 올리고 swap하는 데 필요한 I/O 회수가 줄기 때문에 프로그램이 보다 빨리 실행된다.
라는 이점을 가질 수 있다.
가상 메모리는 실제의 물리 메모리 개념과 논리 메모리 개념을 분리하여 작은 메모리를 가지고도 큰 가상 주소 공간을 프로그래머에게 제공할 수 있다.
가상 주소 공간은
- 프로세스가 메모리에 저장되는 논리적인 모습을 말한다.
- 논리 주소는 0 ~ MAX 까지 연속적인 공간을 차지한다.
- 물리 메모리는 연속적이지 않을 수 있는데 마찬가지로 mmu가 사상한다.
- Shared page를 통해 file과 memory의 공유에 이점을 갖는다.
로 이뤄진다.
10.2 요구 페이징, Demand Paging
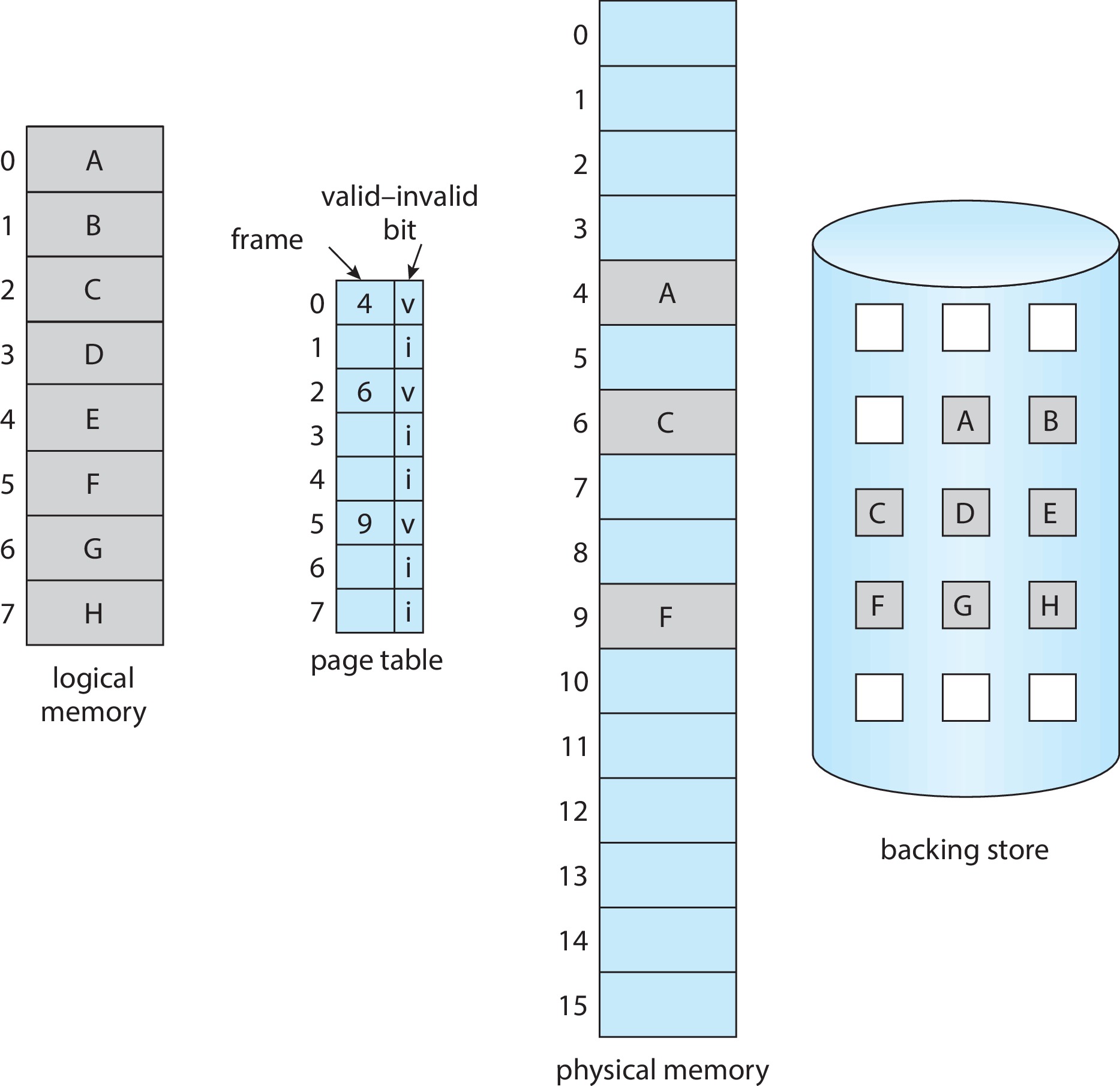
요구 페이징은 필요할 때에만 페이지를 적재하는 기법이다.
- 요구 페이징 가상 메모리를 사용하면, 프로그램 실행 중 요청이 있을 때만 페이지가 로드 된다.
- 액세스 되지 않은 페이지는 물리 메모리에 적재되지 않는다.
- swap-in swap-out은 페이저가 관리한다.
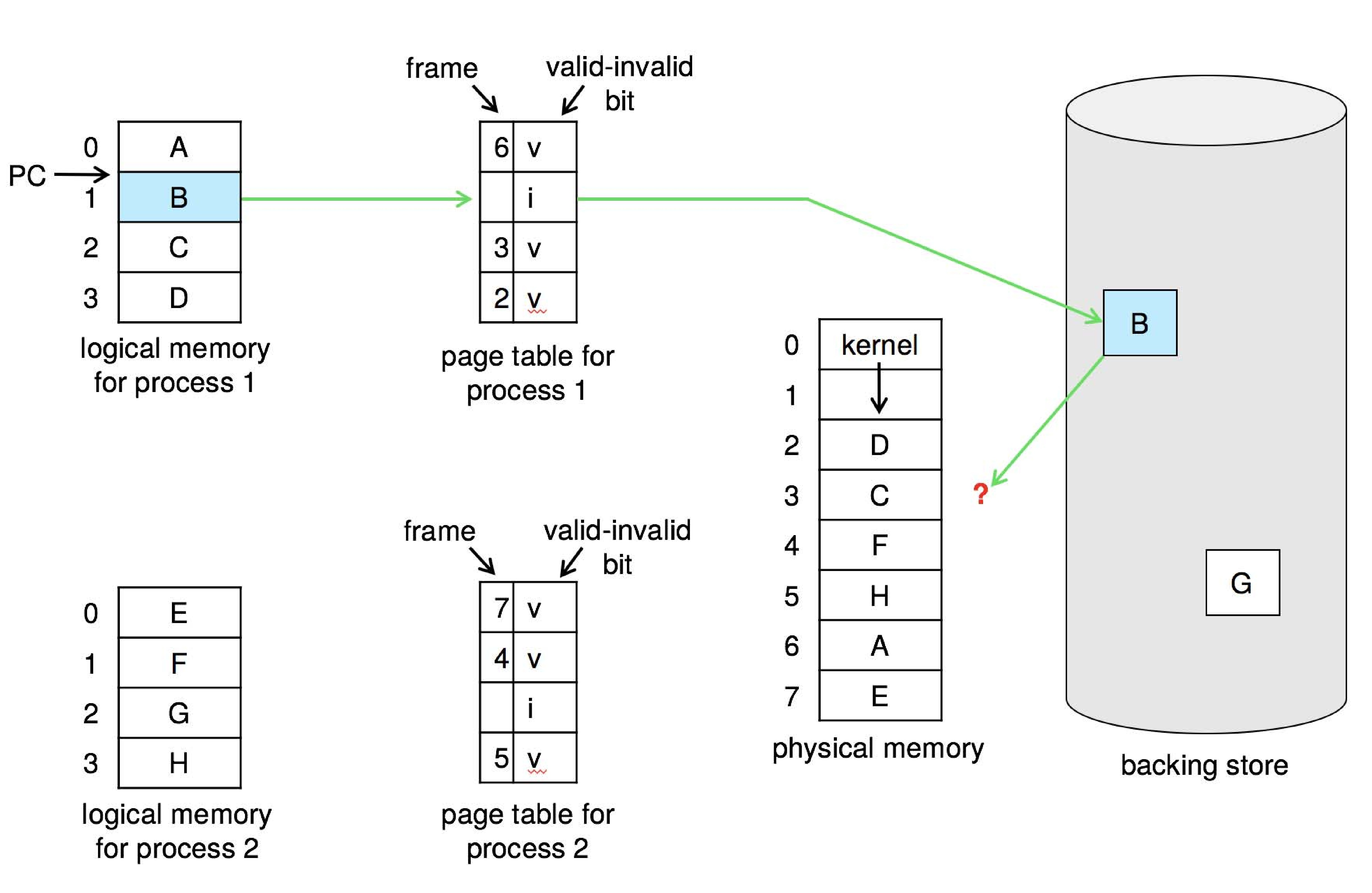
메모리에 존재하는 페이지와 Secondary storage에 존재하는 페이지를 구별하기 위해 하드웨어 지원이 필요하다. 페이지 테이블에는 프레임 인덱스와 함께 유효-무효 비트가 있다.
유효-무효 비트(valid-invalid bit)
- 유효, valid 라면 관련 페이지가 메모리에 존재한다.
- 무효, invalid 라면 페이지가 유효하지 않거나(segmentation fault), 유효하지만 현재 메모리에 존재하지 않고 보조 저장소에 있다는 의미이다.
만약 비트가 무효로 표시되어 있다면,페이지 폴트 Page fault를 통해 무효로 표시된 페이지에 대한 액세스를 시도한다.
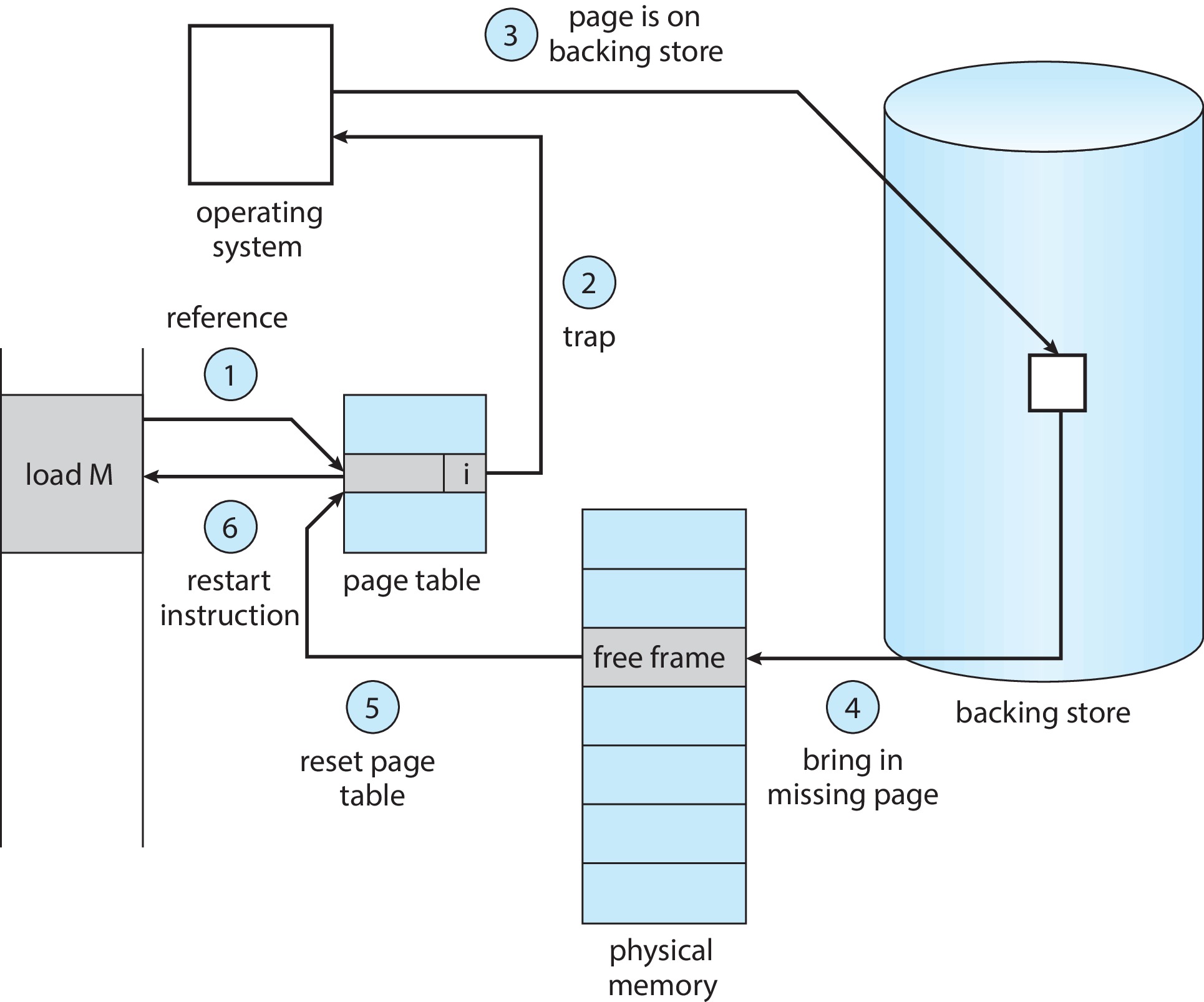
- 유효한 메모리 접근인지, 무효한 메모리 접근인지 확인을 위해 프로세스 내부 테이블(일반적으로 PCB와 함께 유지한다.)을 확인한다.
- 유효하지 않은 경우 프로세스를 종료. 유효하지만 아직 페이지가 메모리에 올라오지 않았다면 보조 저장 장치로부터 가져와야 한다.
- 비어있는 프레임을 검색한다.
- 페이지를 새로 할당된 프레임으로 읽어 들이도록 요청한다.
- 보조저장장치에서 읽기가 끝나면, 내부 테이블과 페이지 테이블을 수정하여 페이지가 현재 메모리에 있음을 나타낸다.
- 트랩에 의해 중단된 명령을 재개한다.
이렇게 필요한 모든 페이지가 적재되고 나면 더 폴트가 발생하지 않는데, 이것을 순수 요구 페이징 pure demand paging이라고 한다.
- 필요할 때까지 페이지를 메모리에 적재하지 않는다.
일부 프로그램은 각 명령을 실행할 때마다 여러 개의 새 메모리 페이지에 액세스 할 수 있다. (명령에 대한 한 페이지, 데이터에 대한 여러 페이지) 따라서 여러 페이지 폴트가 발생할 수 있는데,
참조 지역성 locality of reference
- 어느 한 특정작은 부분만 한동안 집중적으로 참조한다.
- 이러한 성질 떄문에 요구 페이징은 만족할 만한 성능을 보인다.
deman paging을 위한 요구 하드웨어 지원
- 페이지 테이블 : 보호 비트 (page에 대한 접근 권한, read/write/read-only), 유묘-무효 비트 값 설정
- 보조저장장치 : 스왑 공간 (swap space), 메인 메모리에 존재하지 않는 페이지 홀드
가용 프레임 리스트 Free-Frame list
- 페이지 폴트가 발생하고 swap-in 할 때 가용한 프레임의 풀
- zero-fill-on-demand(0으로 채움) 기법 사용으로 보안성 높임
요구 페이징 성능
실질 접근 시간 = (1 - p) * ma + p * 페이지 폴트 시간- 페이지 폴트 처리 시간의 주요 3 작업
- 인터럽트의 처리
- 페이지 읽기
- 프로세스 재시작
- 실질 접근 시간은 페이지 폴트율에 비례한다. (페이지 폴트율을 낮게 유지하는 것이 중요하다.)
10.3 Copy-on-Write
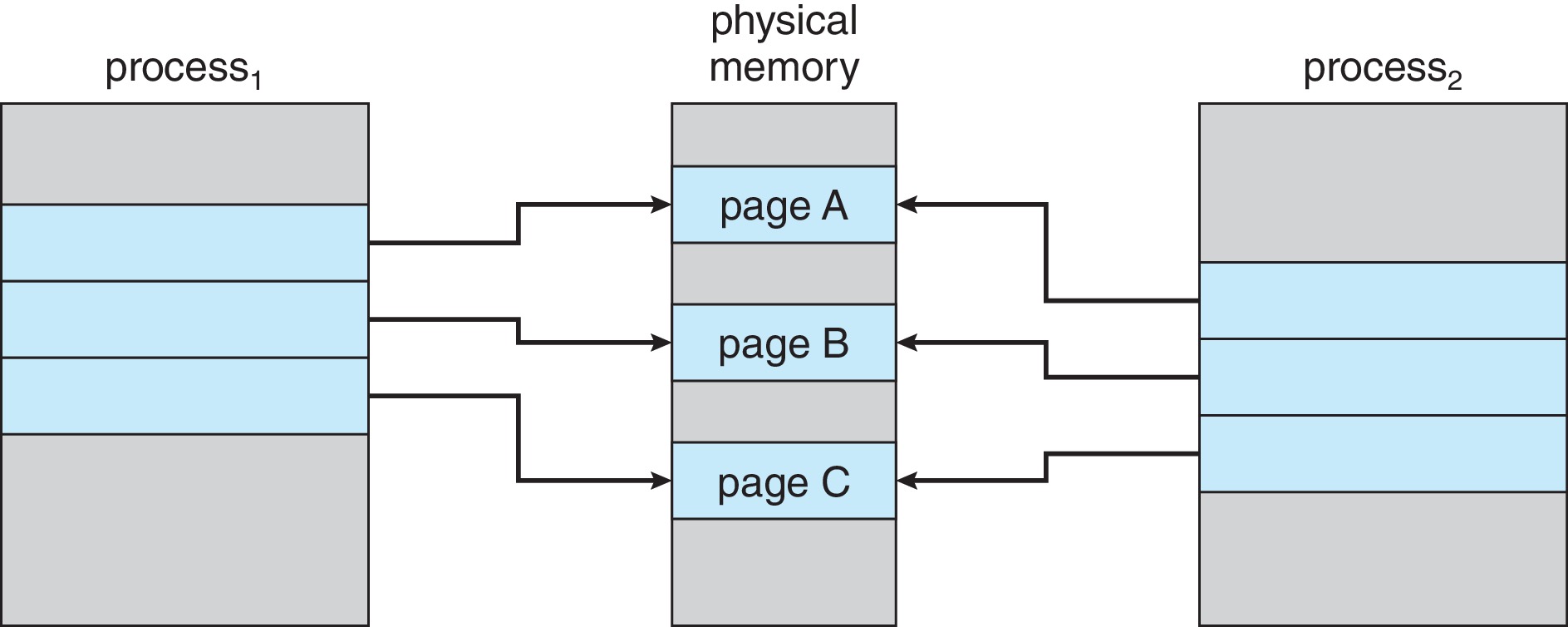
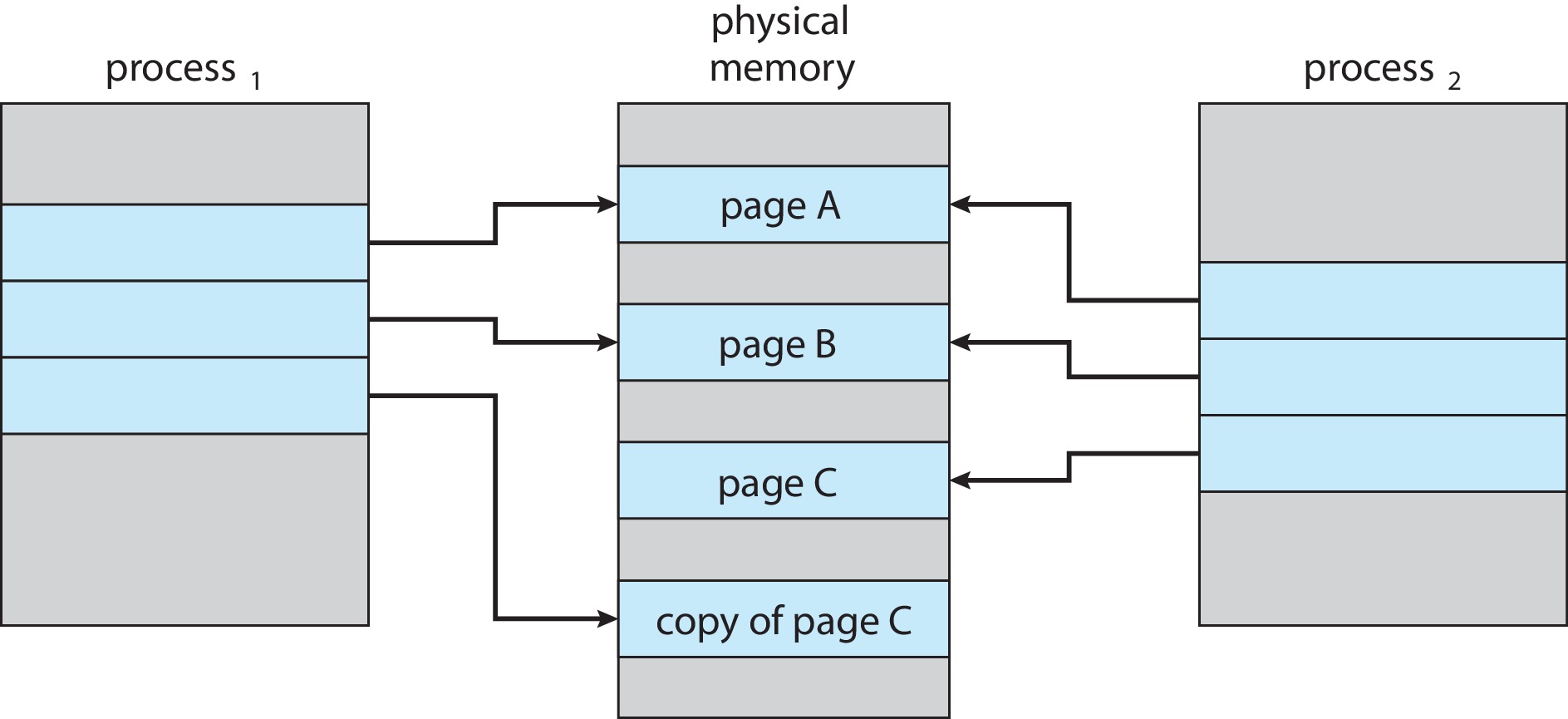
Shared page에 대해 write 할 때에만 copy를 하는 기법이다. 프로세스 생성 시간을 더 줄일 수 있고 새로 생성된 프로세스에 새롭게 할당되어야 하는 페이지의 수도 최소화 할 수 있다. 부모 및 자식 프로세스가 처음에 동일한 페이지를 공유하도록 허용하여 작동하고 프로세스 중 하나가 공유 페이지에 쓰는 경우 공유 페이지의 복사본을 생성한다.
- 자식 프로세스가 페이지를 수정
- 운영 체제는 이 페이지의 복사본을 생성하여 자식 프로세스의 주소 공간에 매핑
- 자식 프로세스는 부모 프로세스에 속한 페이지가 아닌 복사된 페이지를 수정한다.
10.4 Page Replacement 401
다중 프로그래밍의 정도를 높일 수록 메모리 과할당이 발생할 수 있다.
- 유저 프로세스가 실행되는 동안 페이지 폴트가 발생
- 운영체제는 원하는 페이지가 보조 저장소에 있는 위치를 결정하지만, 모든 메모리가 사용 중이므로 빈 프레임이 없음을 확인
이때 프로세스를 종료하거나 페이지 교체를 실행한다.
기본적인 페이지 교체
- 보조 저장소에서 원하는 페이지 위치 검색
- 빈 프레임 찾기
- 빈 프레임이 존재한다면, 사용
- 빈 프레임이 존재하지 않는다면, 페이지 교체 알고리즘을 사용하여 희생 프레임 선택
- 희생 프레임을 보조 저장소에 기록. 그에 따라 페이지 및 프레임 테이블을 변경
- 원하는 페이지를 새롭게 비게 된 프레임으로 읽음. 페이지 및 프레임 테이블 변경
- 페이지 폴트가 발생한 유저 프로세스를 계속 진행
위의 경우 빈 프레임이 없다면, 두 번의 전송이 필요하다.(page-out, page-in) 이때 수정 비트(modify bit or dirty bit)를 사용하여 오버헤드를 줄인다.
- 0 : 변동 없음
- 1 : 변동 있음
페이지의 수정 비트는 페이지의 바이트가 기록 될 때마다 하드웨어에 의해 설정되어 페이지가 수정되었음을 나타낸다. 이 방식은 페이지가 수정되지 않은 경우 I/O 시간을 1/2로 줄이기 때문에 페이지 폴트를 처리하는데 시간을 크게 줄일 수 있다.
요구 페이징 시스템은 두가지 중요한 문제를 해결해야 한다.
프레임 할당 알고리즘 frame allocation algorithm
- 메모리에 여러 프로세스가 있는 경우 각 프로세스에 할당할 프레임 수 결정이 필요.
페이지 교체 알고리즘 page replacement algorithm
- 페이지 교체가 필요한 경우 교체할 프레임을 선택해야 함
참조열 reference string
- 인공적으로 만든 메모리 레퍼런스를 페이지 번호 단위로 나열
FIFO페이지 교체 FIFO Page Replacement
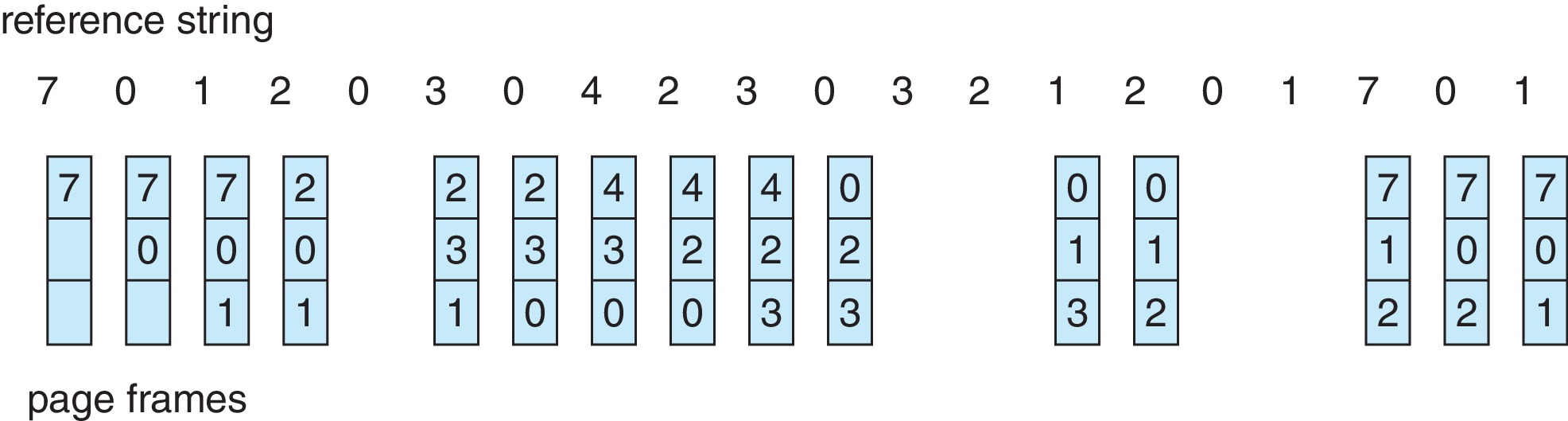
- First in First out
- 이해하기 쉽고, 프로그래밍이 쉽지만
성능 효율이 좋지 않다. - 또한
Belady의 모순 Belady's anomaly가 발생할 수 있다.
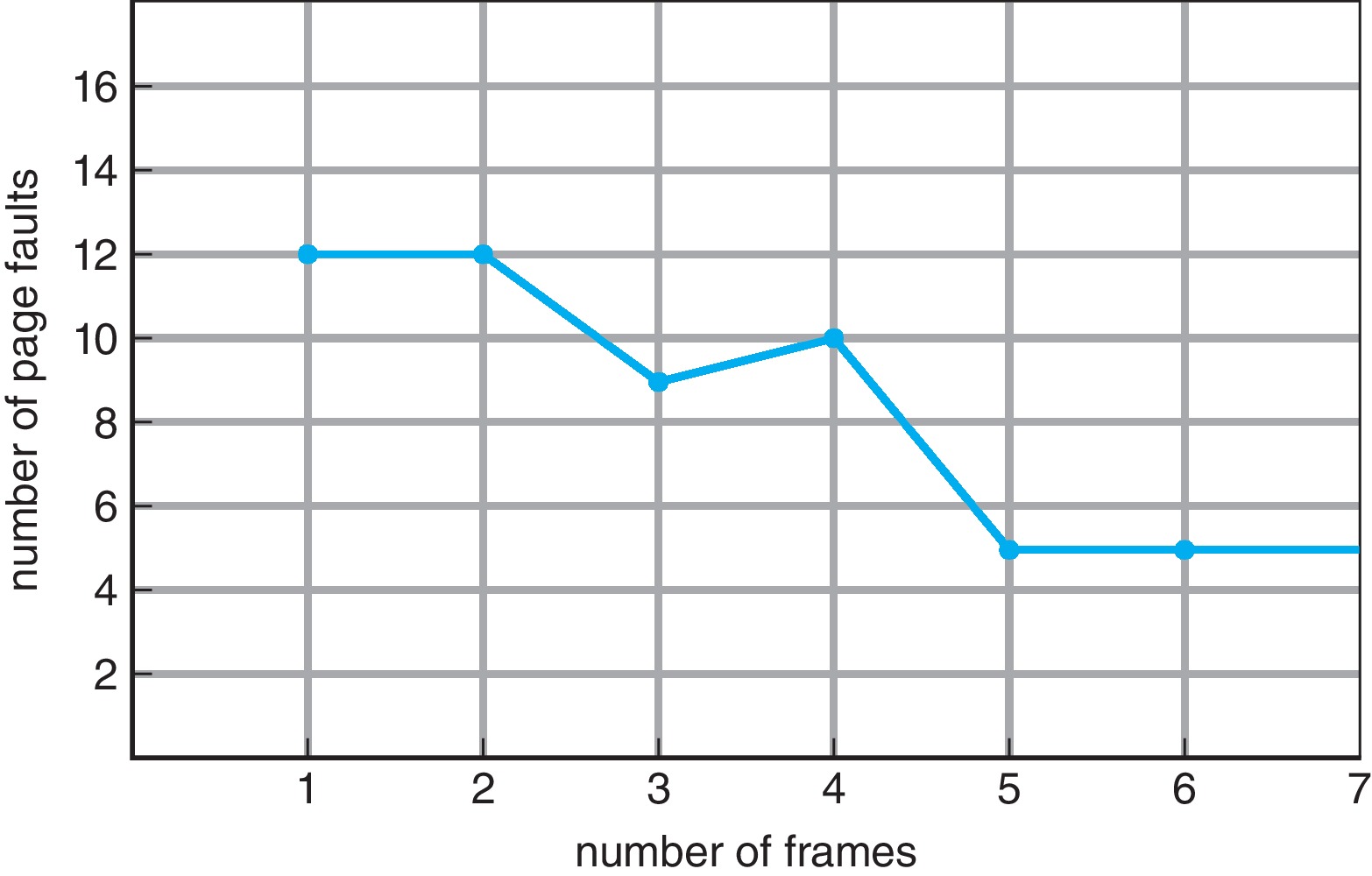
- frame의 수가 커지더라도, page fault가 비례해서 줄어들지 않는 것.
최적 페이지 교체 Optimal Page Replacement
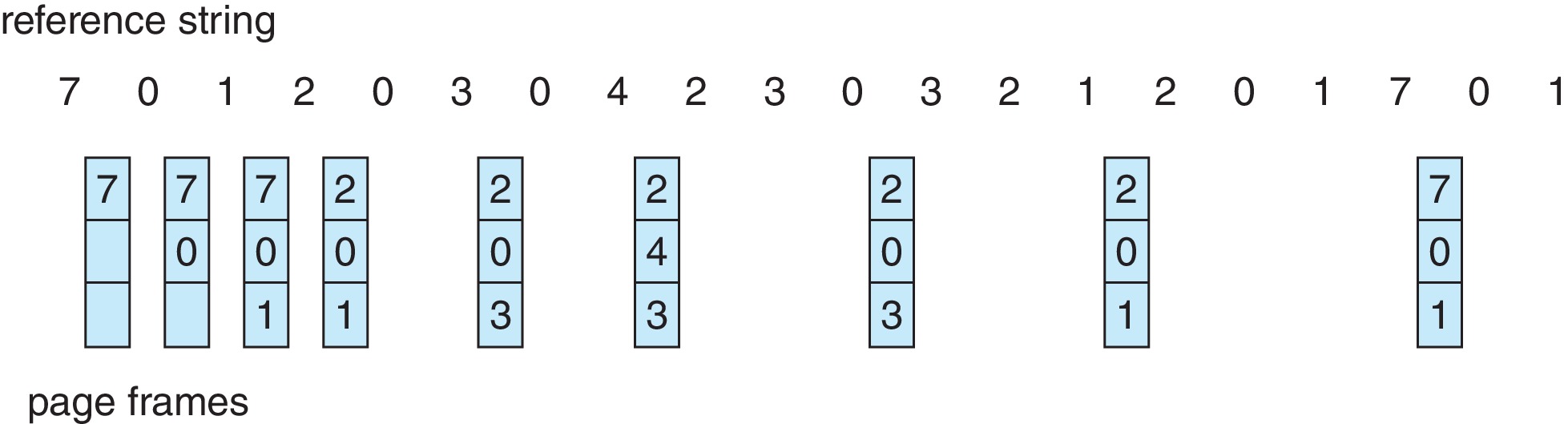
- 앞으로 가장
오랫동안 사용되지 않을 페이지를 찾아서 교체한다. - 구현이 어렵고, 현실적이지 않다. cf) SJF
LRU 페이지 교체
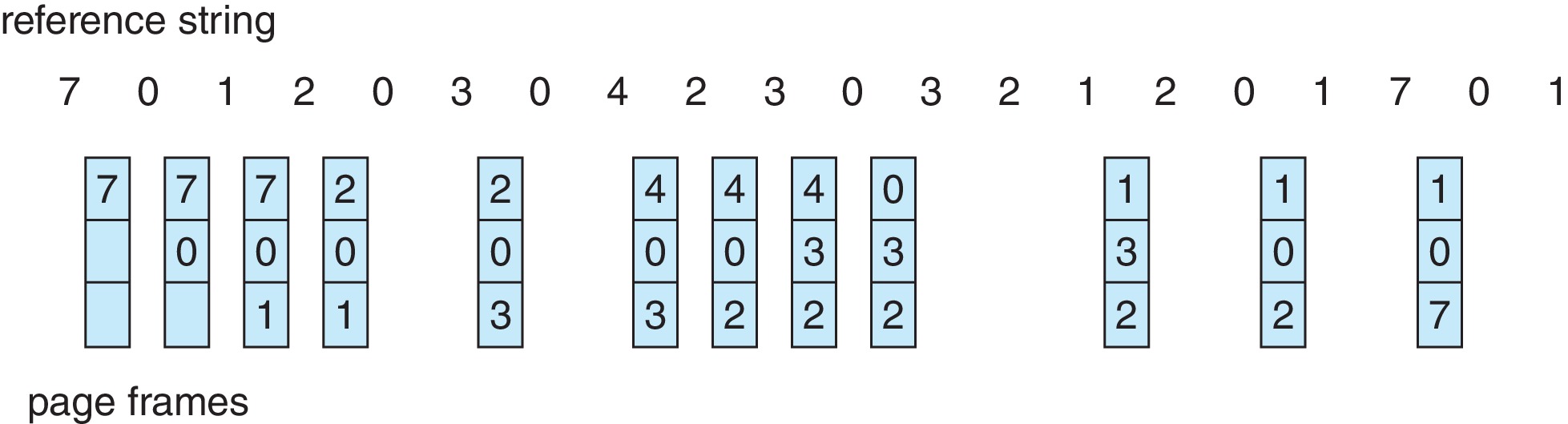
가장 오랫동안 사용되지 않은 페이지를 교체한다.- 실제 구현은 언제 사용되었는 지에 대한 리소스가 많이 들어 어렵다.
LRU 근사 페이지 교체 LRU Approximate Page Replacement
- 실제 사용되는 알고리즘이다.
reference bit == dirty bit를 이용한다.- 0 : 사용하지 않았으므로 페이지를 교체한다.
- 1 : 참조된 페이지이다.
2차 기회 알고리즘 Second-Chane Algorithm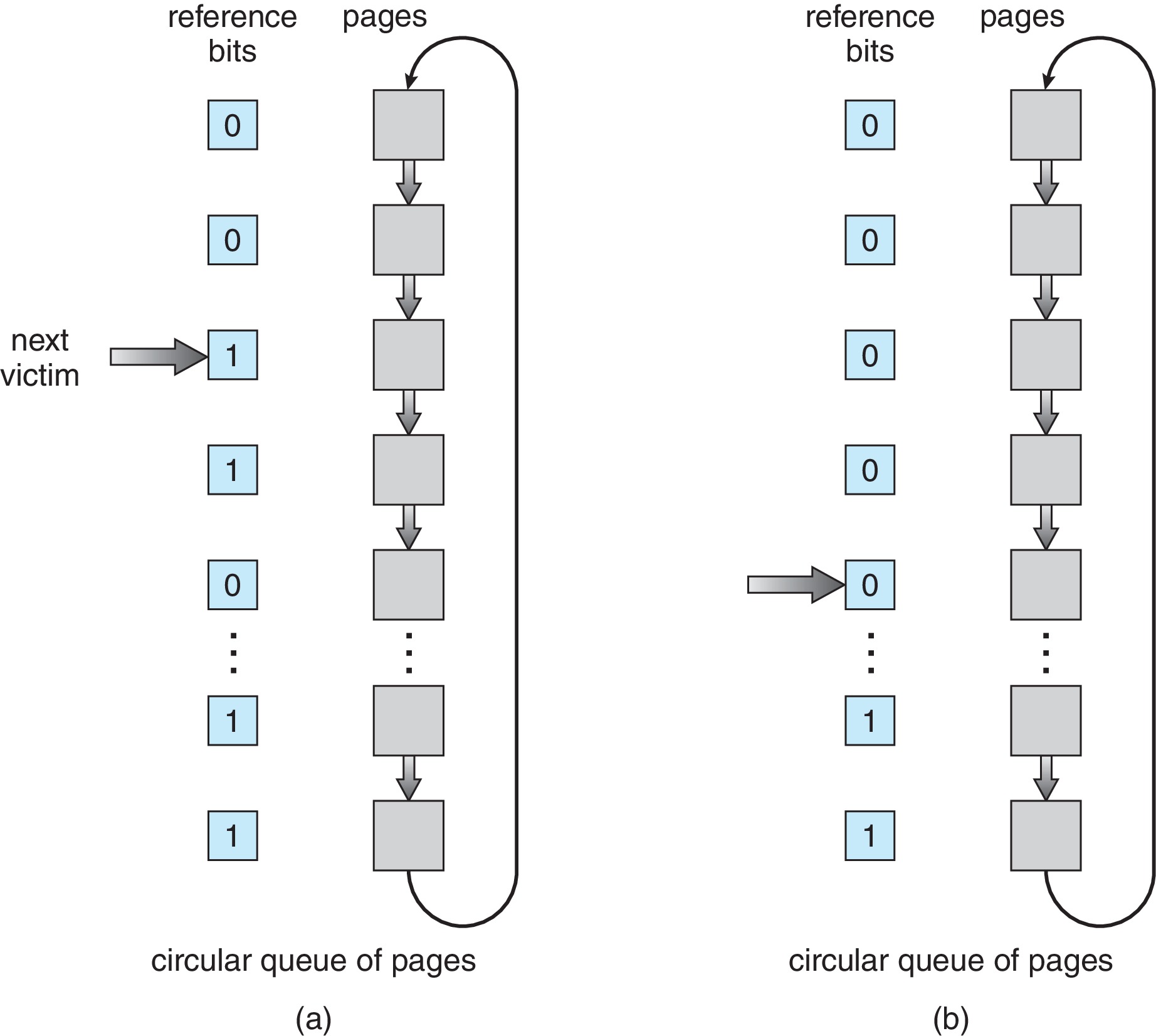
- Circular Queue로 이뤄진 FIFO 교체 알고리즘이다.
- 페이지가 선택될 때마다 참조 비트를 확인한다.
- 0 이면 교체하고 1이면 다시 한 번 기회를 주고 다음 FIFO 페이지로 넘어간다.
개선된 2차 기회 알고리즘 Enhanced Second-Chance Algorithm4가지 등급으로 나눌 수 있다.- (0, 0) : 최근에 사용되지도, 변경되지도 않은 페이지 -> 교체하기 가장 좋다.
- (0, 1) : 최근에 사용되지 않았지만 변경은 된 경우 -> 이 페이지는 뺏어 오려면 디스크에 내용을 기록해야하므로 교체에 적당하지 않다.
- (1, 0) : 최근에 사용되었지만 변경은 되지 않음 -> 다시 사용될 가능성이 높다.
- (1, 1) : 사용되고 변경 됨 -> 사용될 것이며 디스크에 저장해야 한다.
- 계수 기반 알고리즘 Counting-Based Page Replacement
- 각 페이지를 참조할 때마다 계수를 사용한다.
- LFU (least frequently used) 알고리즘
- 참조 횟수가 가장 적은 페이지 교체하는 방법
- 단점으로는, 어떤 프로세스가 초기 단계에서 한 페이지를 집중적으로 사용하지만 그 후로 사용하지 않는 경우 판단이 빗나간다.
- MFU (most frequently used)
- 가장 작은 참조 횟수를 가진 페이지가 가장 최근 참조된 것이고 앞으로 사용될 것이다.
- 페이지-버퍼링 알고리즘 Page-Buffering Algorithm
- 시스템은 프레임 pool 을 가지고 있는다.
- 교체될 페이지의 내용을 디스크에 기록하기 전에 가용 프레임에 새로운 페이지를 먼저 읽어 들이는 방법.
- 이후 교체될 페이지까지 다 쓰여지면 그 프레임은 다시 자유 프레임에 반환
- 또는 원래 임자 페이지가 누구였는지 프레임에 기억해 놓는다.
10.5 프레임의 할당 Allocation of Frames
여러 개의 프로세스들에 제한된 가용 메모리를 어떻게 할당할 것인가에 대한 문제.
균등 할당 (equal allocation)- 모든 프로세스가 같은 개수로 균등하게 프레임을 할당받는다.
비례 할당 (proportional allocation)- 프로세스의 크기 비율에 맞추어 할당받는다.
전역 대 지역 할당 (Global versus Local Allocation)전역 교체 (global replacement): 교체할 프레임을 외부 프로세스에서도 찾는다.- 우선순위가 낮은 프로세스를 희생시켜 우선순위가 높은 프로세스가 더 많은 프레임을 할당할 수 있게 한다.
지역 교체 (local replacement): 교체할 프레임을 내부 프로세스에서만 찾는다.- 할당된 프레임 수는 변하지 않는다.
- 단점으로는 해당 프로세스의 페이징 동작뿐만 아니라
다른 프로세스의 페이징 동작에도 영향을 받는다는 점이다. - 일반적으로
전역 교체가 더 좋은 성능을 나타낸다. -> 많이 사용되는 방법이다.
비균등 메모리 접근 NUMA
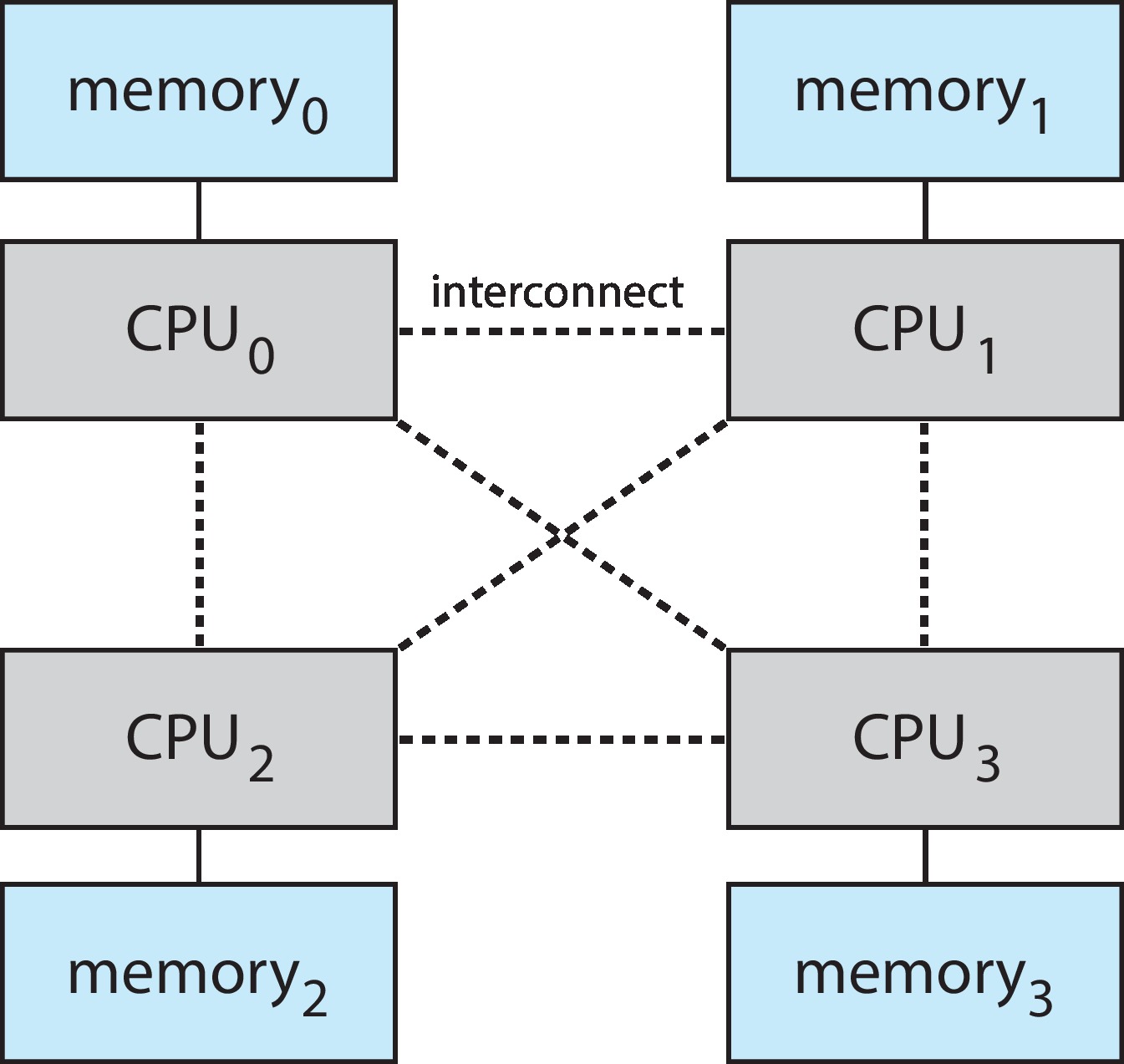 여러 개의 CPU를 가진 `비균등 메모리 접근 NUMA` 시스템에서는 메인 메모리의 일정 영역을 다른 영역보다 빠르게 접근할 수 있다. 다중 CPU 각각에 기본 메모리가 있는 다중 시스템 보드 구조가 이러한 성능 차이를 야기한다. 각자의 로컬 메모리에 접근할 때 빠르게 액세스 할 수 있다. 또한 많은 CPU를 수용할 수 있으므로 높은 수준의 처리량과 병렬 처리를 달성할 수 있다. 이러한 NUMA 시스템에서는 가능한 가장 가까운 메모리 프레임에 할당되도록 하는 것이 목표이다.
여러 개의 CPU를 가진 `비균등 메모리 접근 NUMA` 시스템에서는 메인 메모리의 일정 영역을 다른 영역보다 빠르게 접근할 수 있다. 다중 CPU 각각에 기본 메모리가 있는 다중 시스템 보드 구조가 이러한 성능 차이를 야기한다. 각자의 로컬 메모리에 접근할 때 빠르게 액세스 할 수 있다. 또한 많은 CPU를 수용할 수 있으므로 높은 수준의 처리량과 병렬 처리를 달성할 수 있다. 이러한 NUMA 시스템에서는 가능한 가장 가까운 메모리 프레임에 할당되도록 하는 것이 목표이다.
10.6 스래싱 Thrashing 419
프로세스에 충분한 프레임이 없다면
- 페이지를 교체하고 반복해서 빠르게 가져와야 하는 오류가 발생한다.
- 이러한
과도한 페이징 작업(프로세스 수행보다 page in-out이 더 많은 경우)을스래싱이라고 한다.
CPU는 이용률이 너무 낮으면 새로운 프로세스를 도입하며 다중 프로그래밍 정도를 높인다.
- 폴트를 시작하고 다른 프로세스에서 프레임을 가져온다.
- 다른 프로세스들에서 그 페이지들이 필요해져 다른 프로세스도 폴트를 실행하여 프레임을 가져온다.
- 이 폴트 프로세스는 페이징 장치를 사용하여 swap in, swap out하며 페이징 장치를 대기할 떄 wait queue가 비워진다.
- 프로세스가 페이징 장치를 기다리면 CPU 이용률이 감소한다. -> 또 프로세스를 적재... -> 더 많은 스래싱!
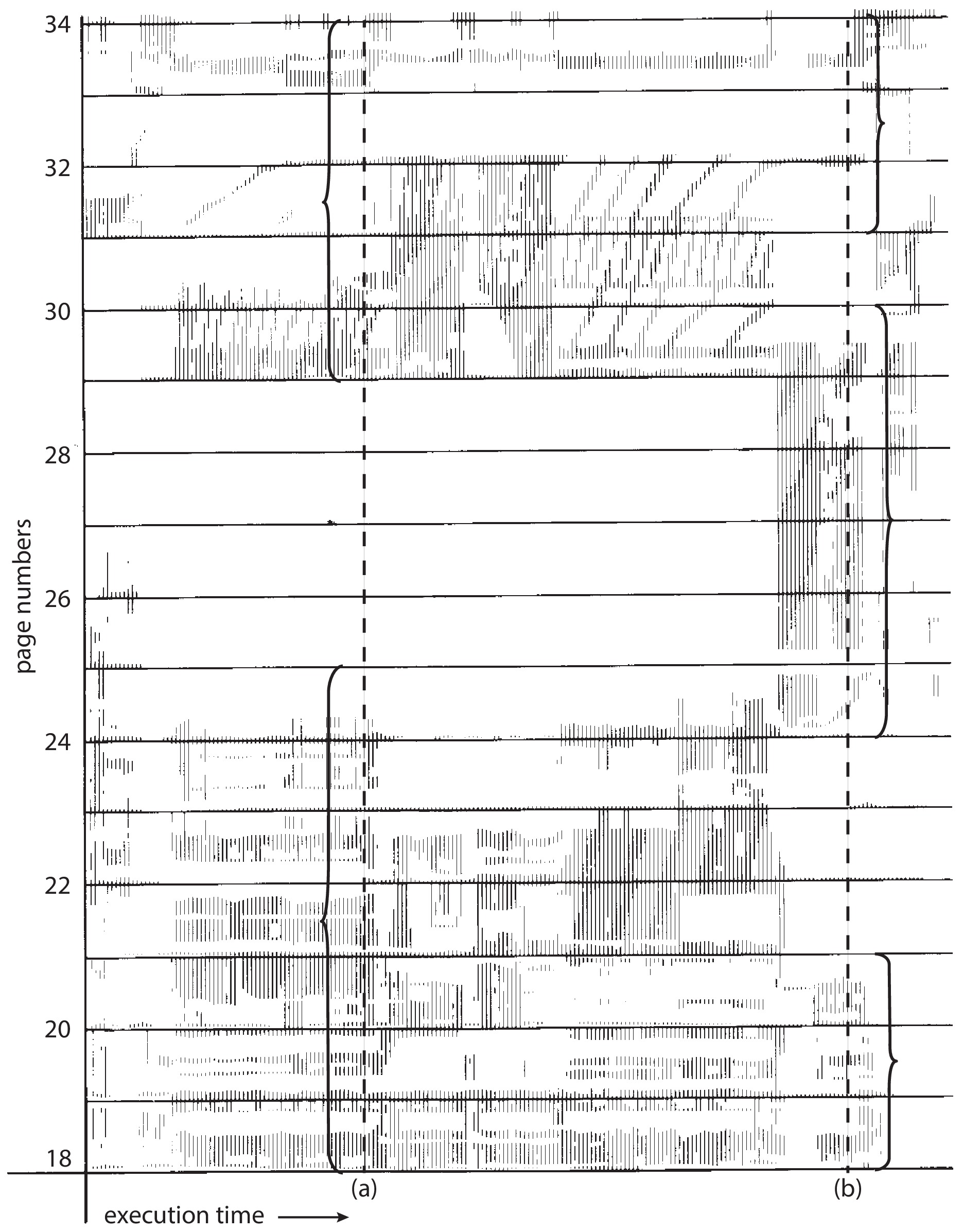
스래싱을 제한하기 위해서는
지역교체 알고리즘 또는 우선순위 알고리즘- 현재 수행중인 프로세스에게 할당된
프레임 내에서만교체 대상을 선정하도록 한다.
- 현재 수행중인 프로세스에게 할당된
지역성 모델 locality model
- 프로세스가 실행될 때에는 항상 어떤 특정한 지역에서만 메모리를 집중적으로 참조하는 것.
- 위를 토대로 필요로 하는 최소한의 프레임 수를 알 수 있다.
스레싱을 방지하기 위해서는 프로세스가 필요한 만큼의 프레임을 프로세스에 제공하면 된다. 아래는 얼만큼 필요한지 산정하는 방법이다.
작업 집합 모델 Working-set Model
- 자주 쓰는 페이지를
집합으로 나타낸다. - 집합은
작업 집합 창 window라고 부른다. - 이루
window 단위로 swap이 이뤄진다.
페이지 폴트 빈도 Page-Fault Frequency, PFF
- 스레싱이란 페이지 폴트율이 높은 것을 의미한다.
- 페이지 폴트율의
상한과 하한을 정해 놓고상한을 넘으면프레임을 더 할당하고, - 하한보다 낮아지면 그 프로세스의
프레임 수를 줄인다.
메모리 압축 Memory Compression
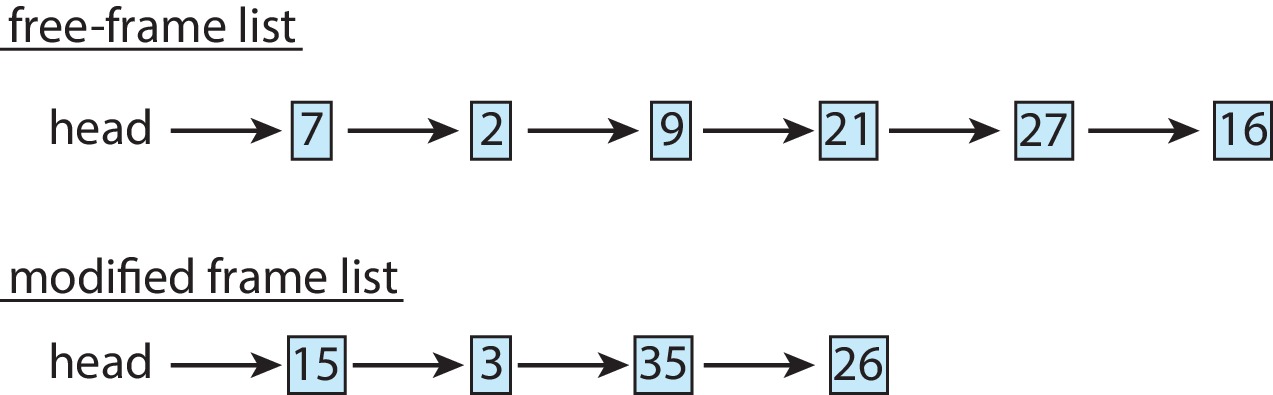 압축 전
압축 전
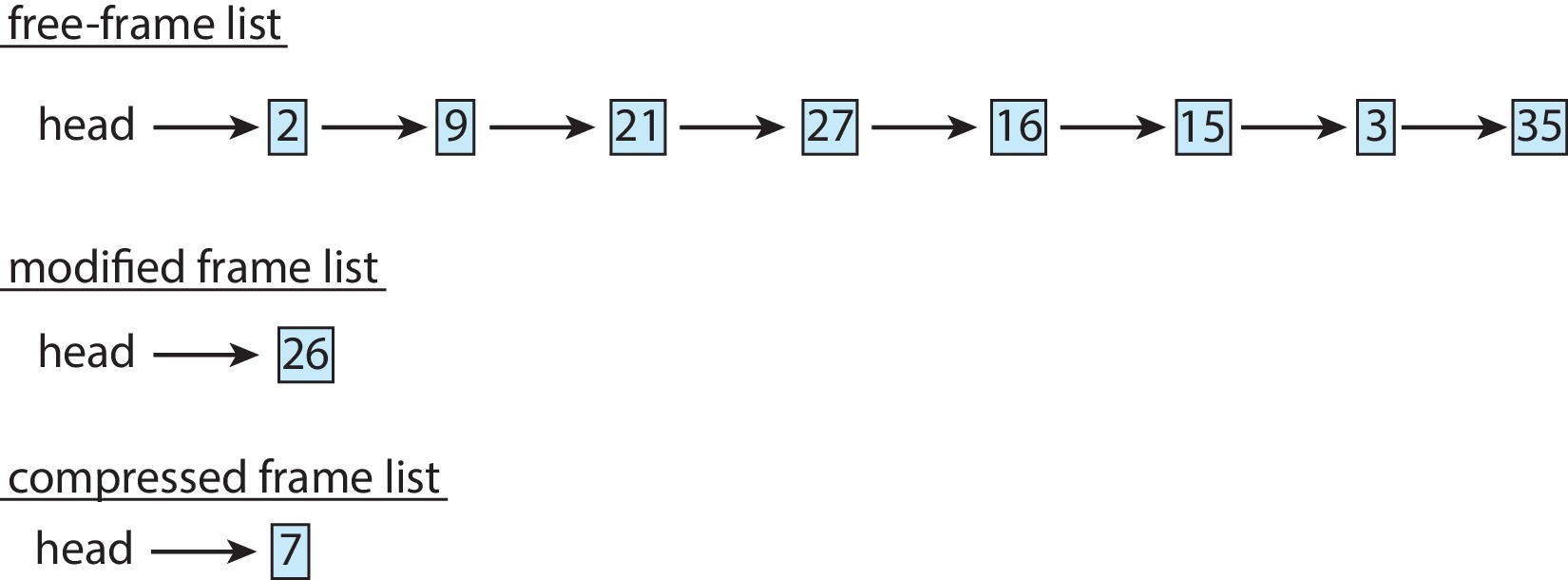 압축 후
압축 후
페이징의 대안(swap에 대한 연산)- 여러개의 가용 프레임을
하나의 가용 프레임 리스트로 구성 -> 스왑 공간에 수정된 프레임 리스트로 저장한다. - 또는
여러 프레임을 압축하고 압축된 버전을하나의 페이지 프레임에 저장한다. - 압축된 프레임 중 하나가 참조되면 페이지 폴트가 발생하고
압축은 해제된다. - 모바일에서는 스와핑을 지원하지 않기 때문에
모바일 운영 체제 메모리 관리의 핵심이다.
커널 메모리의 할당 Allocating Kernel Memory
- 유저 프로세스가 추가 메모리를 요청하면 커널이 가용 페이지 프레임을 할당한다.
- 유저 프로세스가 1Byte를 요청한다면, 페이지 프레임 내부 단편화가 예상된다.
- 하지만 커널 메모리는
별도의 메모리 풀에서 할당받는다.- 많은 운영체제에서는 커널 코드나 데이터를 페이징하지 않기 때문에
낭비를 최소화하기 위함이다. - 베어메탈 시에는
연속적인 메모리가 필요한 경우가 있다.
- 많은 운영체제에서는 커널 코드나 데이터를 페이징하지 않기 때문에
버디 시스템
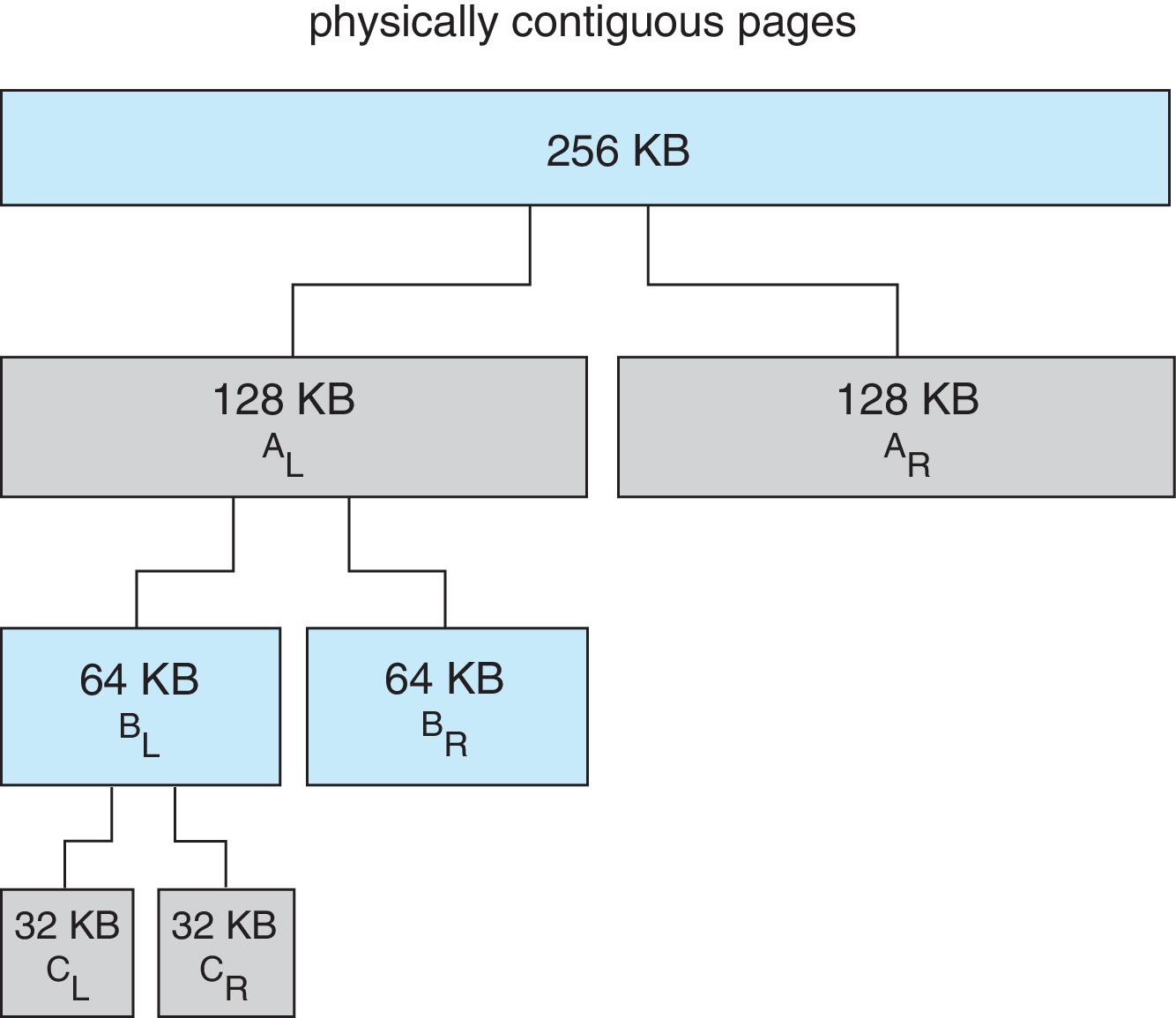
- 연속된 페이지로 이뤄진
세그먼트에서 할당받는다. (2의 거듭제곱 꼴) - 큰 크기의 세그먼트를
절반씩으로 쪼개 나갈 수 있다.(e.g. 256 -> 128 ...) - 마찬가지로
합병(coalessing)하여 합칠 수도 있다. - 가변적이지만,
내부 단편화가 발생할 수 있다. (e.g. 33KB 요청 -> 64KB 할당)
슬랩 할당
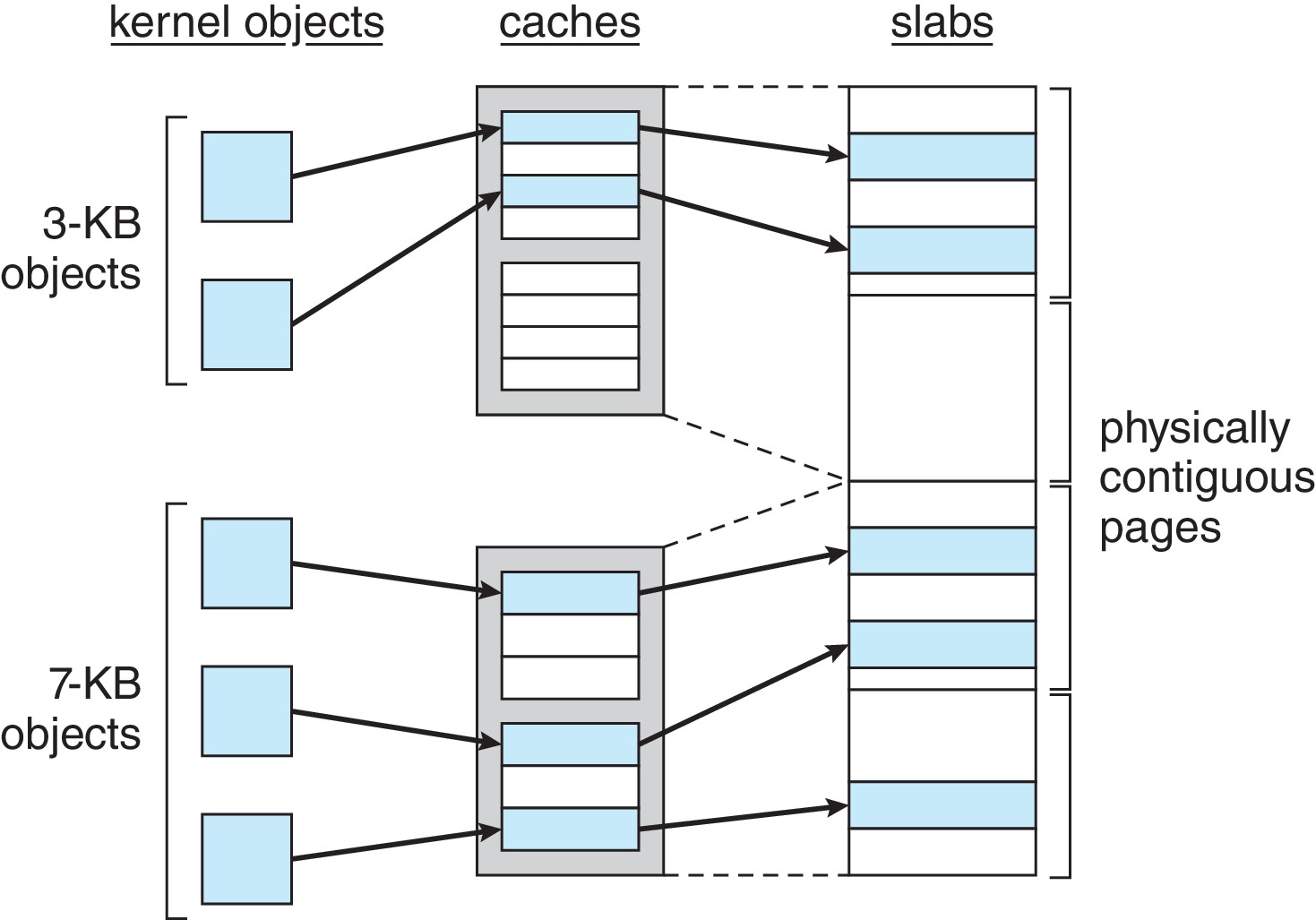
메모리 낭비가 발생하지 않는 방법이다.슬랩(Slab)은 하나 또는 그 이상의 연속된 페이지로 구성된다.캐시(Cache)는 하나 또는 그 이상의 슬랩으로 구성된다.- 커널 자료구조마다
하나의 캐시를 갖고 있고, 캐시는 각인스턴스의 객체로 채워진다. (e.g. fd, file, cache, semaphore...) - 초기의 모든 객체는
free로 표시되고, 할당된 객체는used로 표시된다. - 만약 free 객체가 없는 경우 새로운 슬랩이 연속된 물리 메모리에서 할당되어 캐시에 주어진다.
- 약간 베어메탈인데 페이징한 느낌...
- 장점
- 각 커널 자료구조가 캐시를 가지고 캐시는 객체의 크기로 나눠진 덩어리로 구성되므로
메모리 낭비가 없다. - 객체들이 미리 생성 돼있고, 객체를 사용하면 free 상태로 캐시가 반환되어
메모리 할당과 해제가 빠르다.
- 각 커널 자료구조가 캐시를 가지고 캐시는 객체의 크기로 나눠진 덩어리로 구성되므로
기타 고려 사항 Other Considerations
- 페이징 시스템이 효과적으로 실행되기 위해 고려해야할 추가적 사항들이다.
프리 페이징 Prepaging
- 순수 요구 페이징의 경우 프로세스를 시작하면서 많은 수의 페이지 폴트를 일으키기 때문에 프리 페이징을 통해 방지한다.
- 프로세스마다 작업 집합에 속한 페이지 리스트를 갖고 있고, 작업 집합을 모두 메모리에 올린다.
- 다만 어떤 페이지를 가져와야 하는지 명확하지 않기 때문에 실행 프로그램을 프리페이징하는 것은 어려울 수 있다.
페이지 크기 Page Size
- 이미 존재하는 시스템의 운영체제는 페이지 크기를 빠구는 것이 거의 불가능하지만, 새 시스템을 개발할 때에는 결정해야 한다.
- 페이지 테이블의 크기에 고려하여 결정된다. (프로세스는 각자의 페이지 테이블을 유지해야 하므로...)
- 페이지 테이블의 유지 면에서 페이지는 크면 좋고, 메모리 사용 효율 면에서는 작으면 좋다.
- 페이지를 읽거나 쓰는 것고 고려해야 한다.
- I/O 시간 -> 탐색, 지연시간, 전송 시간
- 페이지가 크다면 탐색에서 이점을 갖고, 작다면 지역성이 향상되어 전체 I/O 시간과 정밀도에 이점을 갖는다.
TLB Reach
- TLB에 사용되는 연관 메모리(associative memory)는 비싸고 전력 소비가 심하다.
- TLB Reach는 TLB로부터 액세스할 수 있는 메모리 공간의 크기를 뜻한다. (항목 수 * 페이지)
- TLB 크기 2배 -> TLB Reach 2배
프로그램 구조 Program Structure
- 요구 페이징의 특성을 이해하면 성능을 올릴 수 있다.
- 예시
int i, j; int[128][128] data;
// 행을 기준으로 워드를 바꿈 -> 페이지가 128워드, 각 행은 한 페이지를 점유
// page fault 128 x 128 = 16384
for (int i = 0; i < 128; i++)
for (int j = 0; j < 128; j++)
data[j][i] = 0;
// 모든 워드를 0으로 한 다음 page fault
// page fault = 128
for (int i = 0; i < 128; i++)
for (int j = 0; j < 128; j++)
data[i][j] = 0;
```
I/O 상호 잠금 (I/O Interlock)과 페이지 잠금(locking)
- I/O가 사용자(가상 메모리) 공간에서 이뤄질 때 메모리에 고정하는 것(pin)이 필요한 때가 있다.
- I/O로 context switch가 일어나서 사용했던 프레임이 덮어 씌어진 경우..
- 해결책 1. 시스템 메모리로 복사해서 디스크에 쓰기 작업을 한다 -> 오버헤드
- 해결책 2. 메모리에서 잠금 비트 lock-bit를 두고 프레임이 잠기면 고려 대상에서 제외한다.
'운영체제' 카테고리의 다른 글
| 입출력 시스템, I/O System (0) | 2022.06.07 |
|---|---|
| 대용량 저장장치 구조, Mass-Storage Structure (0) | 2022.06.06 |
| 페이징과 스와핑, Main Memory (0) | 2022.05.20 |
| 주메모리의 관리 Main Memory (0) | 2022.05.20 |
| 교착상태, Deadlock (0) | 2022.05.15 |

